Markov Chains and Principal Eigenvectors in Network Centrality: PageRank
The pipeline for training a Graph Neural Network can be schematized as follows: Input graph → Structural features → Learning algorithm → Prediction One of the most challenging aspects of this pipeline is the design of structural features. These features aim to capture the essential patterns and relationships within the graph. Automating this process is a key goal in graph machine learning, and it is commonly referred to as feature engineering.
These are few of the possible node level features:
- node degree (treats all neighbours equally)
- node centrality
- clustering coefficient
- graphlets
Different ways to enstablish these features from a graph are:
- engienvector centrality
- betweenness centrality
- closeness centrality (how close to the network)
- and many others
Engienvector centrality
A node is important if surrounded by important neighboring nodes
is a positive constant, it is used to normalize. The basic notion of this feature engineering task is “The more important my friends the more important I am”.
The last equation can be expressed in a matrix form:
This is an eigenvector/eigenvalue equation.
As we will see later, if the graph is undirected and connected, by Perron-Frobenius Theorem the largest eigenvalue is always positive and unique, and the corresponding eigenvector is strictly positive.
The leading eigenvector is used as a centrality score.
It’s not about how many nodes are connected with you, but how important are the nodes that are connected with you.
Eigenvector centrality measures a node’s importance based on of its neighbors, assigning higher scores to nodes connected to other influential nodes. PageRank extends this idea by introducing a damping factor, which simulates random jumps across the network. This adjustment makes PageRank more robust to dangling nodes (nodes with no outgoing links) and spider traps (subgraphs that can trap random walks), which can distort standard eigenvector centrality. By computing PageRank, one effectively obtains a principal eigenvector of the Google matrix, and the resulting scores can be used as features that capture both the structural connectivity and influence propagation in the network. Compared to pure eigenvector centrality, PageRank provides more stable and meaningful importance values, making it a better choice for feature extraction in graph-based learning tasks.
The web is a directed graph
Link analysis algorithms:
- Pagerank
- Personalized page rank
- Random walk with restarst
The PageRank idea:
- All in-links are not equal: some are more important than others
- Recursive nature, the importance of a node is carried by the importance of other nodes.
- A “vote” from an important page is worth more:
If a page with importance has out-links, each link gets votes. Page ‘s own importance is the sum of the votes n its in-links.
So we can define “rank” for a node to be:
… out degree of node .
It’s possible to solve this as a system using gaussian elimination, but it’s not scalable.
We can represent the last equation using the matrix form, we have to introduce the Markov matrix or also called stochastic adjacency matrix. More theory about the Markov stochastic matrix later.
Let page have out-links. If , then .
is a column stochastic matrix, this means that every column sums to 1. Now we can write the equation (2) in matrix form as:
Solving systems of linear equations is a frequent necessity for Web search applications, but the magnitude of computations is usually too large for direct solution methods based on Gaussian elimination to be effective. Consequently, iterative techniques are often the only choice, and, because of size, sparsity, and memory considerations, the preferred algorithms are the simpler methods based on matrix-vector products that require no additional storage beyond that of the original data. Linear stationary iterative methods are the most common.
Appreciate the similarity between this equation and the (1) equation, the only difference is that is the adjacency matrix, while is the Markov matrix or stochastic matrix.
Connection to random walk:
Imagine a random surfer that at some time is on some page . at time te surfer follow an out-link from uniformly at random.
Eventually it ends up in a page linked from .
let be the vector whose coordinates is the probability that the surfer is at page at time . So is a probability distribution over pages.
To compute where the surfer will be at the time we can apply it to the left the column stochastic matrix.
The entry gives the probability that the surfer is on node at time . It is computed by summing the contributions from all nodes that link to . Formally:
Suppose the random walk reaches a state where:
Then is stationary distribution of random walk. Our original rank vector satisfies , that means that our vector is a stationary distribution for the random walk!
How do we solve the equation:
Starting from any vector , the limit is the long-term distribution of the surfers. When applying a linear map again and again, we obtain a discrete dynamical system. We want to understand what happens with the orbit , … and find a closed formula for .
For example:
The one-dimensional discrete dynamical system or has the solution . The value for example is the balance on a bank account which had dollars 20 years ago if the interest rate was a constant percent.
If is an eigenvector with eigenvalue , then and more generally .
The PageRank vector is defined as the principal eigenvector of the transition matrix .
If is the limit of the power sequence as , then satisfies the flow equation:
This confirms that is the principal eigenvector of associated with the eigenvalue . To efficiently solve for in high-dimensional systems (like the web graph), we typically employ the Power Iteration Method.
Summary:
- PageRank measures importance of nodes in a graph using the link structure of the web
- Yo can simulate a random web surfer using stochastic adjacency matrix M
- PageRank solves where can be viewed as both the principle eigenvector of and as the stationary distribution of a random walk over the graph.
Important questions
At this point we have an intuitive knowledge of how this algorithm works, but to properly understand the essence of it, it’s necessary to dive into the mathematics that lies behind the algorithm. We ought to ask ourself these important questions:
- Will this iterative process continue indefinitely or will it converge?
- Under what circumstances or properties of H is it guaranteed to converge?
- Will it converge to something that makes sense in the context of the PageRank problem?
- Will it converge to just one vector or multiple vectors?
- Does the convergence depend on the starting vector π(0)T ?
- If it will converge eventually, how long is “eventually”? That is, how many iterations can we expect until convergence? In the following part of the article, I’m going to answer this questions and provide and example of this algorithm give an instance.
Power iteration
Iterative procedure that will update over time our rank vector . We start initiating every node with an initial state, continue the process until the states stabilizes.
Repeat until convergence:
Initialize Iterate: that is the same of Stop when
About 50 iterations is sufficient to estimate the limiting solution.
Markov matrix
A discrete-time Markov chain is a sequence of random variables with the Markov property, namely that the probability of moving to the next state depends only on the present state and not on the previous states:
If both conditional probabilities are well defined, that is, if
The possible values of form a countable set called the state space of the chain.
The matrix describing the markov chain is called transition matrix, but it’s also very common to call it stochastic matrix.
A stochastic matrix is an matrix where all entries are nonnegative and each row adds up to 1.

- The ROWS represent NOW, or FROM ;
- The COLUMNS represent NEXT, or TO ;
- Entry is the CONDITIONAL probability that , given that : the probability of going FROM state TO state .
A probability vector or stochastic vector is a vector with non-negative entries that add up to one.
A Markov matrix always has an eigenvalue . All other eigenvalues satisfy:
This property ensures the stability of the stochastic process over time.
Proof:
Consider the transpose matrix . Since is row-stochastic, the sum of the entries in each row of is , which means that the sum of the entries in each column of is . Thus
so has eigenvalue with eigenvector
.
Since and have the same characteristic polynomial, they share the same
eigenvalues. Therefore, also has eigenvalue .
Now suppose is an eigenvector of with eigenvalue such that . Then
which grows in length exponentially as . In particular, for large , some entry of must have magnitude larger than .
However, is also row-stochastic (this can be shown by induction), so all its entries are nonnegative and each row sums to . Hence every entry of is bounded by , and multiplying by any probability vector produces another probability vector. This contradicts the assumption that an eigenvalue with exists.
Therefore, all eigenvalues of satisfy , with always being an eigenvalue.
Perron–Frobenius Theory
In a presentation held by Hans Schneider titled “Why I Love Perron–Frobenius”, he addressed how the Perron-Frobenius theory of nonnegative matrices is not only extremely useful, but it is also among the most beautiful theories in mathematics.
The applications involving PageRank, HITS, and other ranking schemes help to underscore this principle. A matrix A is said to be nonnegative when each entry is a nonnegative number (denote this by writing ). Similarly, is a positive matrix when each > 0 (write ). For example, the hyperlink matrix H and the stochastic matrix M that are at the foundation of PageRank are nonnegative matrices, and the Google matrix G is a positive matrix. Consequently, properties of positive and nonnegative matrices govern the behavior of PageRank, and the Perron–Frobenius theory reveals these properties by describing the nature of the dominant eigenvalues and eigenvectors of positive and nonnegative matrices.
For a matrix , the spectral radius is defined as
that is, the maximum absolute value among the eigenvalues of .
In Perron’s theorem, we set , meaning that the eigenvalue under consideration is precisely the one with the largest modulus.
For positive matrices (), this eigenvalue is real, positive, simple, and associated with an eigenvector having all positive components.
If with , then:
- .
- (the Perron root).
- (simple root).
- There exists an eigenvector such that .
- The Perron vector is unique:
- is the only eigenvalue on the spectral circle.
- Collatz–Wielandt formula:
Perron’s theorem for positive matrices is a powerful result, so it’s only natural to ask what happens when zero entries appear. Not all is lost if we are willing to be flexible. The next theorem says that part of Perron’s theorem for positive matrices can be extended to nonnegative matrices by sacrificing the existence of a positive eigenvector for a nonnegative one.
Perron’s Theorem for Nonnegative Matrices
If with , the following statements are true:
- (note that is possible).
- There exists an eigenvector such that .
- The Collatz–Wielandt formula remains valid.
Irreducibility and Connectivity
A square matrix is irreducible if and only if its directed graph is strongly connected.
Equivalently, for each pair of indices there exist and intermediate indices such that:
Another equivalent characterization is: is irreducible if and only if there does not exist a permutation matrix for which:
where and are square blocks. In other words, cannot be put into a nontrivial block upper-triangular form.
Perron-Frobenius Theorem
Frobenius’s contribution was to realize that while properties 1, 3, 4, and 6 in Perron’s theorem for positive matrices can be lost when zeros creep into the picture (i.e., for nonnegative matrices), the trouble is not simply the existence of zero entries, but rather the problem is the location of the zero entries. In other words, Frobenius realized that the lost properties 1, 3, and 4 are in fact not lost when the zeros are in just the right locations—namely the locations that ensure that the matrix is irreducible. Unfortunately irreducibility alone still does not save property 6— it remains lost.
Let be an irreducible matrix with . Then:
- .
- (the Perron root).
- (the Perron root is simple).
- There exists an eigenvector such that:
- The Perron vector is the unique vector defined by: Except for positive multiples of , there are no other nonnegative eigenvectors of , regardless of the eigenvalue.
- need not be the only eigenvalue on the spectral circle of .
- Collatz–Wielandt formula:
where
Irreducible Markov Chains
Analyzing limiting properties of Markov chains requires that the class of stochastic matrices (and hence the class of stationary Markov chains) be divided into four mutually exclusive categories.
-
M is irreducible with existing
(i.e., M is primitive). -
M is irreducible with not existing
(i.e., M is imprimitive). -
M is reducible with existing.
-
M is reducible with not existing.
Let be the transition probability matrix for an irreducible Markov chain on states , and let be the left-hand Perron vector for (i.e., , ).
The following hold for every initial distribution :
-
The step transition matrix is .
The -entry in is the probability of moving from to in exactly steps. -
The th step distribution vector is given by
-
If is primitive (aperiodic), and if is the column vector of all 1’s, then
-
If is imprimitive (periodic), then
and
-
Regardless of whether is primitive or imprimitive, the component of represents the long-run fraction of time that the chain is in .
-
The vector is the unique stationary distribution vector for the chain, because it is the unique probability distribution satisfying
So we have seen that a unique positive PageRank vector exists when the Google matrix is stochastic and irreducible. Further, with the additional property of aperiodicity, the power method will converge to this PageRank vector, regardless of the starting vector for the iterative process.
Implementation
Problems to handle: If there are:
- pages with dead ends (have no out-links)
- Spider traps (all out-links are within the group) Our random walk could fail. The solution for spider traps is teleport, at each time step, the random surfer has two options:
- with probability , follows a link at random
- with probability , jump to a random page
- Common value for are 0.8 to 0.9
For dead ends, the solution is teleport with probability . The spider traps are not a mathematical problem, simply the result is not what we want. On the contrary, Dead-ends are a mathematical problems since our matrix wouldn’t be anymore a column stochastic matrix.
This allows us to the final matrix, also called the google matrix, it has the shape of:
Where in this case is just the stochastic matrix . Here we don’t simulate the random walk, we think of it of being run infinitely long, computing this is equal to solve this recurvie equation by computing the leading eigevector of G.
So random walk is just an intuition that we never truly simulate.
Example:
Take this graph, the goal will be to extract the feature that better represent the importance of each node in the over all graph.
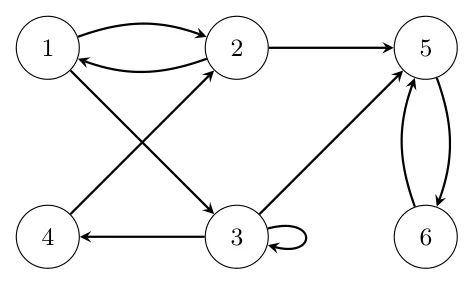
The first step through the process is to represent the graph as an adjacency matrix:
The matrix is going to be a matrix. We set if page has a link to page and otherwise.
Note that the in the diagonal happen only if there is a self loop.
Next we are going to assume that every link in that column are equally likely (equal probability out-links), so we divide every single entry of a column by the number of in that column. Since the columns must summ up to 1.
Now we need to eliminate spider-traps and dead-ends.
Do have this result we have to use the definition of google matrix I provided before:
The middle step for computing this summation of matrixes is this:
As the final result, you can see how the property of stochastic matrix remained, but we have a full matrix that avoid problems like spider-traps and dead-ends.
Now we can iterate until we find a stable state:
- Initialize
- Iterate:
- Stop when
After few iteration (according to the epsilon you chose), you will arrive in a stable solution that in my case is:
You can try this for yourself just executing the pythong code you will find below.
from fractions import Fraction
G = [
[Fraction(1,40), Fraction(18,40), Fraction(18,40), Fraction(1,40), Fraction(1,40), Fraction(1,40)],
[Fraction(35,40), Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(37,120), Fraction(1,40)],
[Fraction(1,40), Fraction(1,40), Fraction(18,40), Fraction(35,40), Fraction(37,120), Fraction(1,40)],
[Fraction(1,40), Fraction(18,40), Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(1,40)],
[Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(35,40)],
[Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(1,40), Fraction(37,120), Fraction(1,40)]
]
# Initial rank vector (uniform)
r = [Fraction(1,6) for _ in range(6)]
# Stopping threshold epsilon
epsilon = Fraction(1,1000)
def multiply_matrix_vector(M, vec):
"""Multiply matrix M by column vector vec (both using Fraction)"""
result = []
for row in M:
s = sum(r*c for r,c in zip(row, vec))
result.append(s)
return result
def vector_diff(v1, v2):
"""Max absolute difference between two vectors"""
return max(abs(a-b) for a,b in zip(v1, v2))
# Iterative multiplication until convergence
iteration = 0
while True:
r_next = multiply_matrix_vector(G, r)
diff = vector_diff(r, r_next)
iteration += 1
print(f"Iteration {iteration}: {r_next} | diff = {diff}")
if diff < epsilon:
break
r = r_next
r_final = [round(float(x), 5) for x in r_next]
print("\nConverged PageRank:")
for i, val in enumerate(r_final, 1):
print(f"Node {i}: {val}")This vector represents the importance of the nodes in the graph. A representative image of the importance of nodes in the graph is provided below.
Although node 5 receives links from nodes 2 and 3, its PageRank is relatively small. This is because PageRank distributes a node’s “importance” proportionally across all of its outgoing links. Node 2 and node 3 each link to multiple nodes, so the portion of their rank that reaches node 5 is only a fraction of their total importance. In other words, PageRank measures the probability that a random surfer lands on a node, taking into account both the importance of linking nodes and how their rank is split among their outgoing links. Therefore, even if a node is linked by important nodes, it may still have a low rank if those nodes distribute their rank widely.
References 📚
Research Papers
- Jure Leskovec et al., Pixie: System for Large-Scale Graph Mining, PDF
- Bindel, Lecture Notes CS6210, Cornell University, PDF
- Vesak, Stochastic Processes Notes, PDF
Books
- Horn, R.A. & Johnson, C.R., Matrix Analysis, 2nd Edition, PDF, p. 549
- Langville & Meyer, Google’s PageRank and Beyond, PDF, p. 186
- Horn & Johnson, Matrix Analysis, Chapter 8, PDF
Markov Chains & Linear Algebra
- Knill, Lecture Notes on Markov Chains, Harvard University, Lecture 33, Lecture 34
- Knill, Linear Algebra Probability Summary, Lecture 36
- MathOverflow, Examples on Non-Diagonalizable Stochastic Matrices, Link
Exercises
- Knight, Markov Chains Exercise Sheet with Solutions, PDF
- Probability Course, Solved Problems, Link
- Gordon, Solved Problems on Markov Chains, PDF